
In the rapidly evolving landscape of financial technology, AI solutions have become integral to improving customer experience and optimizing operational efficiency. Our recent project focused on deploying an AI-based loan prediction system with enhanced support through loan policy and counseling services. The journey involved meticulous model training, integration of Retrieval-Augmented Generation (RAG), and overcoming key technical challenges. Below, we break down the process and outcomes of this development, providing insight into how the architectural design supports the system’s functionality.
Training the Model: From Data to Decision-Making
At the core of our solution is a Machine Learning (ML) model, designed to predict loan approval or rejection based on various customer attributes. The training started by gathering and preprocessing historical loan data, including diverse attributes such as income level, credit score, employment details, and other financial factors. The primary challenge here was ensuring that the model not only learned from this dataset but also generalized well to unseen data.
We trained the model using a mix of supervised learning techniques, fine-tuning hyperparameters and optimizing it to improve prediction accuracy. The model’s current performance, though commendable, still takes approximately 26 seconds to generate predictions. On top of that, we integrated a new layer in the prediction pipeline(XAI) to explain the model prediction of why the loan is approved or rejected. To mitigate this, we are exploring possible refinements in the model’s internal structure to speed up inference time without compromising prediction quality.
Leveraging RAG for Personalized Counseling Services
One of the unique aspects of this system is its integration of Retrieval-Augmented Generation (RAG). The RAG approach was employed to enhance customer support by offering personalized counseling services. Unlike standard generative models, RAG retrieves relevant information from an internal vector database before generating a response.
In our setup, RAG is particularly useful for providing loan-specific advice, as it extracts relevant information from pre-existing counseling documentation of that particular organization and then tailors responses based on the customer’s profile and loan query. For example, if a loan officer inquires about loan approval and rejection of a specific application, RAG can pull data on applicable loan policies and generate a precise, contextually rich recommendation.
We refrained from using any cloud-based AI solutions like OpenAI’s GPT-4 due to privacy concerns, opting for an open-source model (Llama 3.1). While this decision allowed us to maintain full control over user data, it did slow down the LLM’s response time, making it roughly five times slower than cloud-based counterparts. However, we anticipate significant performance improvements as we transition the model to a web environment and explore system optimizations.
Architectural Overview
The architecture supporting this AI solution is both flexible and scalable, designed with future enhancements in mind. The core components of the system include:
Front-End Interface:
We have chatting interfaces for users, and we saved the chats in the UI for better user experiences. We are sharing some sample UI designs with the following link
Here is the sample of an LLM response below where the loan is approved. The response is generated concisely and to the point with the proper explanation.
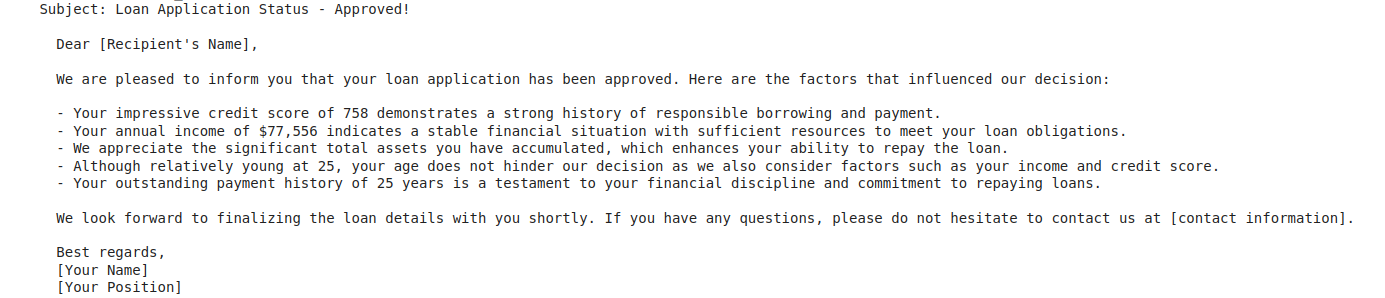
Fig: Sample Response of Approved Loan Application

Fig: Overall Architecture of the RAG Integrated Loan Application Decision Prediction
Backend AI Models:
The backend consists of two primary models, our own ML loan prediction model and the RAG-enhanced LLM for counseling services. Both of these models work independently but feed data into a unified interface.
Loan Approval model:
The ML model gives the decision of loan approval. It is a supervised classical ML model that takes the input of users’ different financial attributes and gives the decision of loan approval(e.g. Yes or No).
This Loan approval model can also explain the reasons for loan approval decisions using explainable AI(XAI). We integrated explainable AI with Shapley values(SHAP). This explainable AI module enables the system to be user-friendly and acceptable. When a user requests for a loan, our XAI can explain his/her terms and conditions for loan application decisions.
Fig:
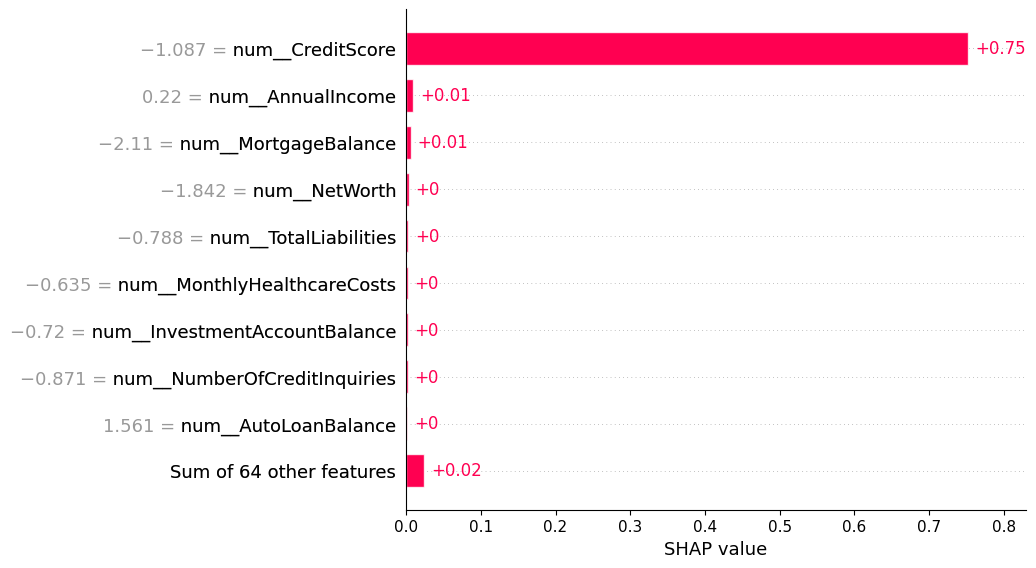
Fig: Shap Values of Important Features
Suppose, in the above figure, we can see the SHAP values of different important features. For example, in this example Credit Score is the most important feature among all. It has the highest SHAP value than others. Secondly the Annual Income and Mortgage Balance are also important features for loan approval decisions. When our ML model gives the decision of loan approval, it also explains why the loan is approved or rejected by the particular reasons. These reasons are identified by the explainable AI(XAI) more specifically by the SHAP values of the features.
RAG-enhanced LLM:
Retrieval-augmented generation (RAG) is the process of optimizing the output of a large language model, so it references an authoritative knowledge base outside of its training data sources before generating a response. In our application, we integrated RAG to store the documents of the organization as their policies, rules, and other information. We created the vector database using chroma_db and created the knowledge base of the loan application policies. This organization’s information and policies are the reference of the LLM responses. When a user queries and gives his/her question, there can be two types of chatting.
- Chatting with a loan application: Provide the loan application and the text and find a response.
- In general chat, send a text and wait for a response.
In both cases, we used to generate responses from LLM with reference to company information and policies using RAG.
For the first case, chatting with a loan application for loan acceptance, or rejection, we upload the user’s financial attributes and other information with the prompt. Our system can handle user information with the prompt and find out the predictions of loan approval decisions with proper explanation. This decision along with the prompt goes inside the LLM for generating responses. The LLM either explains why the loan is approved or why it isn’t with clear explanations and reasons.
For the second case, in general chat, we only chat with the LLM. There is no loan application decision, rather, LLM will give suggestions to users on how he/she can get a loan and other information. The RAG ensures that the LLM generates contextualized responses for the users.
Storing Conversational History:
One challenge with locally deployed language models is their inability to handle conversational context automatically. To address this, we implemented a custom mechanism using Langchain to track user interactions and maintain conversation history. This approach enables the model to deliver contextually accurate responses throughout a customer’s session.
Data Management Layer:
The data layer manages loan application records, user profiles, and the linked PDF document detailing loan policies and counseling services. We acknowledge that a more detailed and accurate PDF will be provided by the business, further enhancing the model’s decision-making capabilities.
The architecture’s modularity allows for easy integration with other systems, and its reliance on local models makes it a reliable choice for organizations that prioritize data privacy.
LLMs:
We used open-source LLM models in our application. We used the Ollama embedding to run the LLM. Ollama offers support for various models, and one of them is the Mistral model. We also used the llama 3.1 model.
Mistral:
Mistral is a powerful language model developed to offer high performance with fewer parameters, making it more efficient and scalable than many larger models. Mistral 7B gives various benefits like fine-tuning support. It responds faster and generates promising responses. As we are using open-source LLM models, we consider the mistral model as our LLM
Llama 3.1:
Llama 3.1 is part of Meta’s series of open-weight large language models, building upon the success of previous versions like Llama 1 and 2. LLaMA 3.1 allows easy fine-tuning for domain-specific tasks. Researchers and developers can customize it to specific applications, improving accuracy in targeted domains without needing to train from scratch. We also created the domain-specific task and Llama 3.1 can give us the best support for our goals.
Associated Researchers:







